When defining bounding boxes for frames where the object to be detected is not rectangular, should you define the box to be just big enough to fit the entire object in it? Or should you cut out part of the object so that a greater percentage of the bounding box has the object in it? Does it matter?
Well, let’s see here - let’s answer a few questions.
What is a mace? It’s a ball with spikes on the end of a club. But what if I don’t want to put the bounding box on the whole mace, just around the round ball part? Well, since you’ve identified only the round ball part the model may not recognize the fact that it’s a ball with spikes at the end of a club. In essence, your model might recognize every ball as being a mace.
What is a bear? It’s a big animal with fur and paws and a snout. If you drew the bounding boxes just around the body of the bear, the model may only recognize the fur - other animals with the same fur would be confused with a bear. A bear rug could be confused with a bear. A dark mink coat might also be confused with a bear.
The bounding box identifies the object. Include the entire object, if you want the model to recognize the entire object. Include portions of the object if you want the model to try to recognize just portions of the object as being the object. I mean, a floating head should probably still be recognized as a person, no? The model will only recognize what’s inside the bounding box, and will ignore anything not within bounding boxes. Excluding things from the bounding box says, “that other stuff doesn’t matter.”
Interesting… so if we are only trying to detect a team element, I’ll interpret this as the bounding boxes should be tight on the team element. We are only trying to detect a known scenario. Whether a mace or a ball is in front of us, we just need to know where that something is that is about to hit us so we can react in time! We are not going to have worry about novel objects being introduced and mistaken for team elements since we know the field setup, so for this use case, we want a tight border of the team element for success.
Is it beneficial to have other field elements such as the bar codes in the picture frames? If the bounding box defines the team element, but the picture frame has the bar codes in it, is the Tensorflow model learning to ignore the bar codes? Or does it just ignore everything else in the picture frames since everything else that is not in the bounding box is categorized as “that other stuff doesn’t matter.”?
Good stuff - thanks for bearing with us (cringe).
The Bounding Box should be as tight on the team element as you can, while making sure to capture everything that is important about your team element. Having a bounding box that is too large may pick up too much of the background, and if all of your images include the background the model might see the background and say, “oh, there’s always a background in there.” Even though the background is also being added as “ignore this”, the bounding box information is presented to the model and the model still has to make the determination of what to include or not.
Well, yes and no. You’re trying to detect an object. The object you see isn’t going to be pixel perfect to the object images you’re training with (shadows, light reflections, color variations, white balancing, blurry images, etc…) will be potential issues. It’s best to give the model as much information with as many variations as possible, and let the model sort out
If it’s possible that the bar codes could be confused with part of your team element (for example a portion of your team element has the same color patch as the Bar Code), if it’s impossible to put a bounding box around your team element without including a bar code in your bounding box, or if you find the model inexplicably recognizing the bar code as an object but you absolutely did not mean for it to, then you should make sure the bar codes are present in the image frames but are not themselves labeled. This will allow your TensorFlow model to learn to ignore the object. Otherwise, there’s no need; if you didn’t label a bar code anywhere, and your object doesn’t in some part look like a bar code (to you), it’s unlikely you need to “train” TensorFlow to ignore the bar code.
To specifically answer your question, yes, TensorFlow essentially learns to ignore “background segments” in frames that are not labeled (outside of bounding boxes). However, training and evaluation frames are chosen at random, and if you were going to “train” TensorFlow to “ignore” specific “background segments” you’d need to make sure a significant number of frames contained the “background segments” you’re trying to ignore (trying not to say the word “object” because TensorFlow doesn’t really know if what it’s looking at is an “object” unless the model comes back with a possible detection).
As a follow up, we tried putting the bounding box totally within the team element that has distinctive thick horizontal stripes. We were trying to define the box so that no gray mat would be in the box. We ran the training and got terrible results - nothing was detected in the testing data.
We then took the same video and put a larger box around the team element with some background and it was able to detect the team element in the test data.
When you say, “nothing was detected in the testing data”, what was your minimum result confidence set to (you’d find that in the tfodParameters.minResultConfidence variable). By default the minimum result confidence value is set to 0.8f, which honestly is way too high for developing a model. Setting that to 0.25f or lower for testing can provide you a much better indicator of what the model actually “sees”. If the model detection is higher, you would want to set the minimum higher in order to filter out unwanted or spurious output.
What I meant by “nothing was found in the test data” was we looked at the model results of the evaluation data on the models tab in the ml tool chain after training 1000 steps and clicked on the images tab that showed the evaluation frames side by side. There we found that there were no frames on the Labeled by Tensorflow left side that showed any bounding box being detected compared to the 100 percent manual labeled box shown on the right.
I don’t see a place that users control the minimum confidence that the evaluation data shows in the ml tool chain. I’ve seen for some evaluation frames in the early first 100 steps of training where the bounding boxes come back with values as low as 51%.
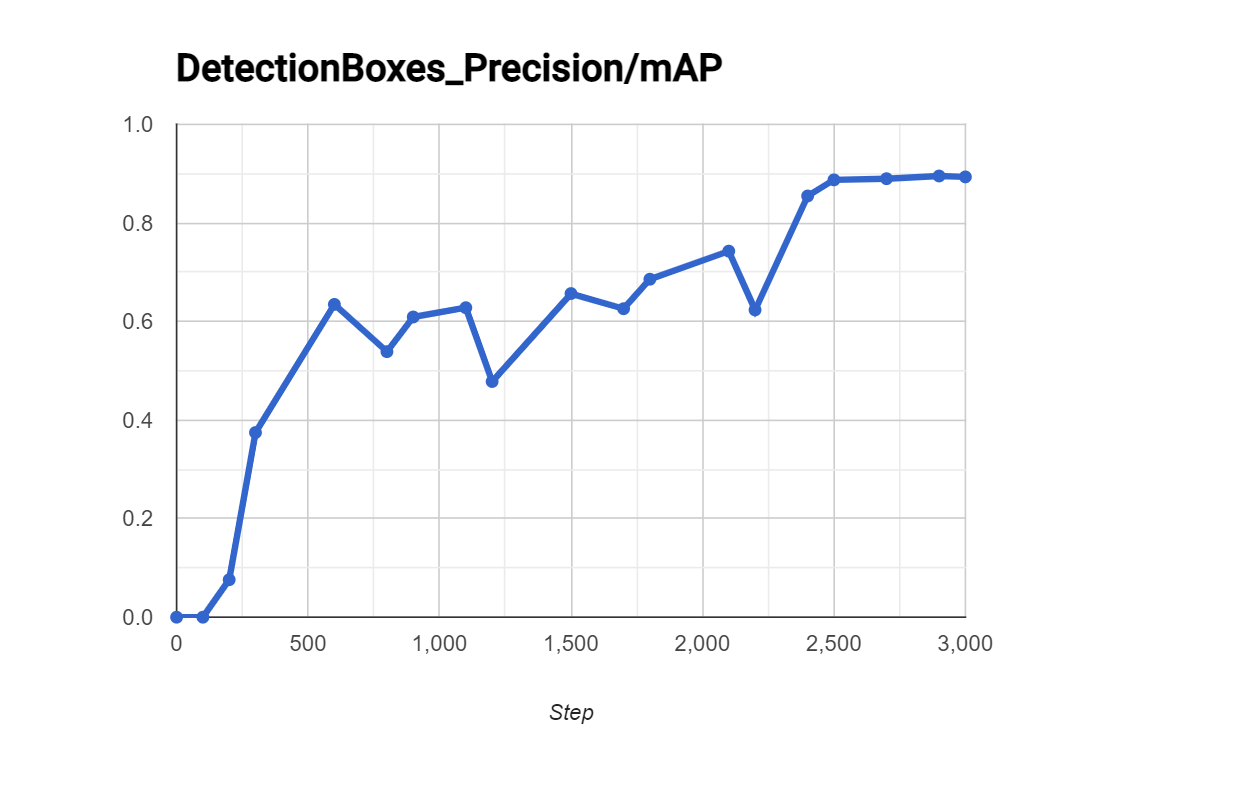
Could you send screenshots of what the graphs (AR, mAP, and IOU in particular) in the graph tab look like. Those can give a better representation of the model. I have attached some example graphs below to show you what you are looking for in that graphs tab. This is not to say that those are the graphs of an ideal model
Also when Danny was talking about the minResultConfidence he was referring to actually running the model using the built in integration with TFOD in the FTC SDK. This is set with all the other parameters in your TFObjectDetector.Parameters object. In the sample the min confidence is set as 0.8 as seen here. For testing models you may want to start lower and work your way up from there.


Thanks for taking a look at this experiment.
First we took a video and labeled boxes that were thinner to completely fall on the element we are trying to detect. The idea was that we were trying to uses the distinctive pattern to help the recognition. Images look like this:

We trained this dataset that has just 33 frames for 1000 steps, and results were as follows:



No evaluation images had any box successfully Labeled by Tensorflow at 1000 steps so we considered this to be a poor result.
Next we used a copy of the video, and labeled boxes that were just big enough that they would fit the entire object and but have some background in them that looked like this:

Again we trained this dataset that has just 33 frames for 1000 steps, and results were as follows:



All the evaluation images had 1 box successfully Labeled by Tensorflow with > 81% at 1000 steps so we considered this successful…
Is this consistent with what you would expect, and is it fair to draw any conclusions on how to draw bounding boxes?