Yes! Thank you for letting me comment publicly, I think this could help a lot of people.
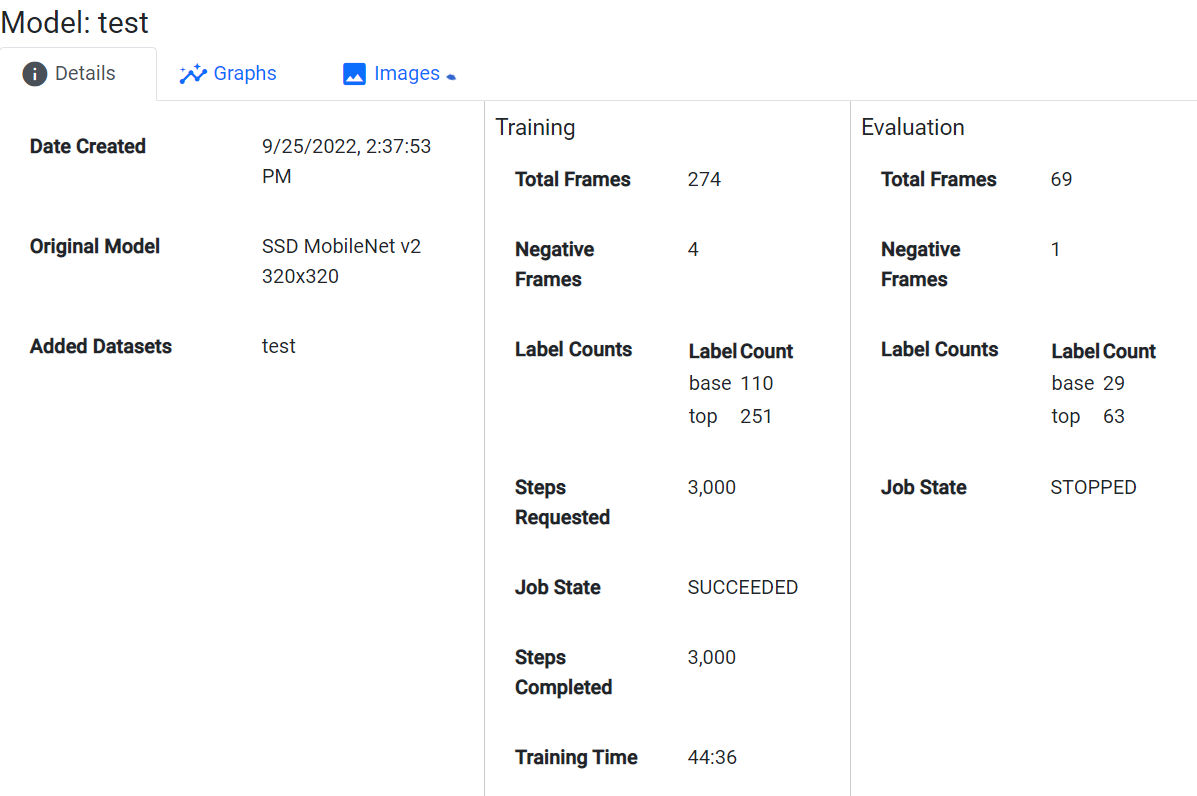
The first item I wanted to talk about is the video orientation. It appears that you took this video with a cell phone - that’s fine, and you even took the video in a reasonable resolution, so well done. However, you took this video in portrait mode - on the robot the video will likely never be in portrait mode (unless you know how to ask the camera to rotate the image before presenting it to Vuforia). It makes a big difference because of the downscaling that will occur - in order to be processed by the base model, the image is going to be downscaled to a 300x300 pixel square. Things look very different in portrait vs landscape when this kind of downscaling occurs - images will look “stretched” in the short direction vs “elongated” in the long direction because of this downscaling. The model doesn’t know “which end is up” so the effect can be detrimental to the model. Always make sure you take the video in the same orientation that the camera on the robot will be seeing things.
Let’s again talk about downscaling. On a 1280x720 image that gets downscaled to 300x300, an object that is 140px x 115px gets downscaled to 32px x 27px - that’s what the model itself will see. If you have very small objects in the image, it’s dubious whether or not the model is going to be able to accurately train and identify those objects when they’re that small scaled down. All hope isn’t lost, though, just understand that object recognition might suffer. You want the largest objects in the image that you can, and you want a lot of variation in the size of the object. If the object could be seen as 300x400 pixels, make sure some of your training frames have the object at 300x400 pixels in the training data (and a good bit of variation in-between).
Ok, let’s talk now about labeling, and specifically “inconsistent labeling.” One of the mantras you have to take with machine learning is “Garbage in, Garbage out.” If you provide bad labeling, the model is going to be bad. Let’s take a couple examples:
Here’s a small montage of how you labeled “Top” - when labeling objects, you want to always provide consistent labels that always shows the object consistently within the bounding box with a little room on each side for background. Frame 1 had a great label for “Top”, but very very few frames had reasonable labels afterward (bounding box only covers a small percentage of the object you want to track, includes other objects that might be classified differently, or completely missed the mark altogether). If you want the model to consistently know what a “Top” is, it needs to be consistently labeled. If you’re using a tracker you need to always watch that tracker and stop tracking when it goes off the rails, fix it, and resume.
It’s also important to recognize that frame 301 had no labels, but it was not marked as an ignored frame. When you look at the Datasets, frames that are not marked as ignored but have no labels are known as “Negative” frames. Negative frames should NEVER have objects in them that you want to identify - they are only used as providing “ignore everything in this frame as background” to the model training. Frame 301 is considered a “Negative” frame, but had one of the best images of the “Top” that you could provide, which likely confused the neural net so that it didn’t know what it should be looking at. Be careful when you have Negative frames - make sure they are intentional!
So now let’s look at a small montage of how you labeled “base”:
Again, inconsistent labeling. You started and finished strong, but too many of the frames in-between are a hot mess (excuse the phrase). You didn’t have many frames with a Base in them to begin with, so every improperly labeled frame hurts your detection massively!
But what I noticed more is what you didn’t label. How many bases are in the image? do you eventually want the model to label this as a base?

If so, not labeling them in every frame tells TensorFlow “ignore anything that looks like this.” The problem with that is that some of the images you “ignored” look a LOT like the ones you DON’T want to ignore (some of these ignored areas look a lot like a “base” in frames 687 and 203).
I hope this helps you!
-Danny