Our first real attempt to train a model and test it on our robot had mixed results. The images tab for our built model led us to believe that both our objects (an FTC cube and a red solo cup) were being detected by tensor flow at ~90%. However upon loading this model into android studio and running it on our robot, we found that the cup was simply never detected. The cube was detected, though not as well when using FTC’s provided Freight Frenzy model (not too surprising).
The fact that one of the objects was not detected at all, especially when there were no warning signs in the results makes me wonder if this might not be a bug?
This is possibly a result of a poorly trained model. There would be no warnings for this other than the model not working well. Your model is only as good as what you train it with. I would recommend pointing your camera at one of your training frames (you can either point it at your monitor or print out the image). The images tab only gives you the accuracy of the specific instances you trained for, not the breadth of the scenarios the model will see in real life. For a better representation please consult the the Graphs Tab. While daunting it gives good data. Section 5.8 of the ftc-ml manual has great information explaining each one of the graphs. However this will only give you a good representation of the accuracy when running on the frames you provided the trainer with. This is why giving the trainer images that represent the use case is important.
To get an idea of what training images/videos to use consults section 7 of the ftc-ml manual.
Another possibility is that you have either loaded the wrong model or not entered the correct labels. Make sure to double check that those are all correct. Please consults Section 6 of the ftc-ml manual for more details.
Thanks Uday!
I really liked the idea of pointing our robot’s camera at our monitor, showing one of our training frames. It still did not recognize the object, which I still find very surprising. This is basically an identity test, I would think.
I’ve reviewed the sections you’ve recommended, and double checked the actual robot code, and I’m still at a loss, especially why one object (an FTC cube) is getting detected and not the other. Might this have something to with the fact that we are using the SSD MobileNet v2 320x320 model?
We’re going to try again with a fresh video and see if we get any improvement.
Interested to know if you found a solution to this. We seem to be in the same boat. Our training returned our object (a blue tube) at 97% but the “tube” isn’t detected when running our code. We’re at a loss for what step we’ve missed or what we’ve done wrong?? (We also tried to point the camera at our monitor as suggested and it didn’t recognize the object).
We’re hunting this forum for help while waiting for a new video to train…
(Also our software team is coding in Blocks)
Since the height of your object basically takes up the full height of the frame, did you make sure to turn the zoom back to 1 from the default of 2.5 in your program? In our tests of a custom model, the zoom made things worse from a detection standpoint (inconsistent when zoomed in at 2.5 where it only saw a portion of the object, performed much better with the zoom at 1).
UPDATE: We have started from scratch, using just a single object this time, and it works! Things that we did differently that might have helped:
just one object this time
used a wider variety of distances and angles for the training video
made sure that the background was almost exclusively the gray tile mats
rejected many frames where the video image was distorted or blurred
Now, it very consistently recognizes our object when the background is mostly the gray tile mats. We get lots of false detections when we randomly point our camera away from the playing field, which makes sense to us, since our videos almost exclusively contained the gray tile mats.
Overall, a successful test! I think that we’re ready to contemplate how we would do this for the competition scenario.
Thanks everyone!
Hey Liz! Sorry for the delayed response. Our team only meets once a week. Here is the pic of our blocks you asked for. We are still unsuccessful in our attempt to train our model. I’ll upload some pics from today. We also started over, following @paulmarganian suggestions and didn’t have much luck.
In the setModelFromFile block, the Labels socket is filled with a list that should contain all the labels that were in your training data. It looks like you just have one label “cone” in that block.
To add more, you’ll need to click on the gear icon on the create list with block. That will allow you to add more items to the list.
No worries. We appreciate any help we can get!! Yeah we deleted everything related to the “tube” that we made last week and started over. Now we’re using the red “cone” and seem to be having the same issues. Honestly, we’re not really sure what step we’re missing or what we’re doing wrong. The labeling/training all process successfully, but when we implement the code it fails to recognize our object.
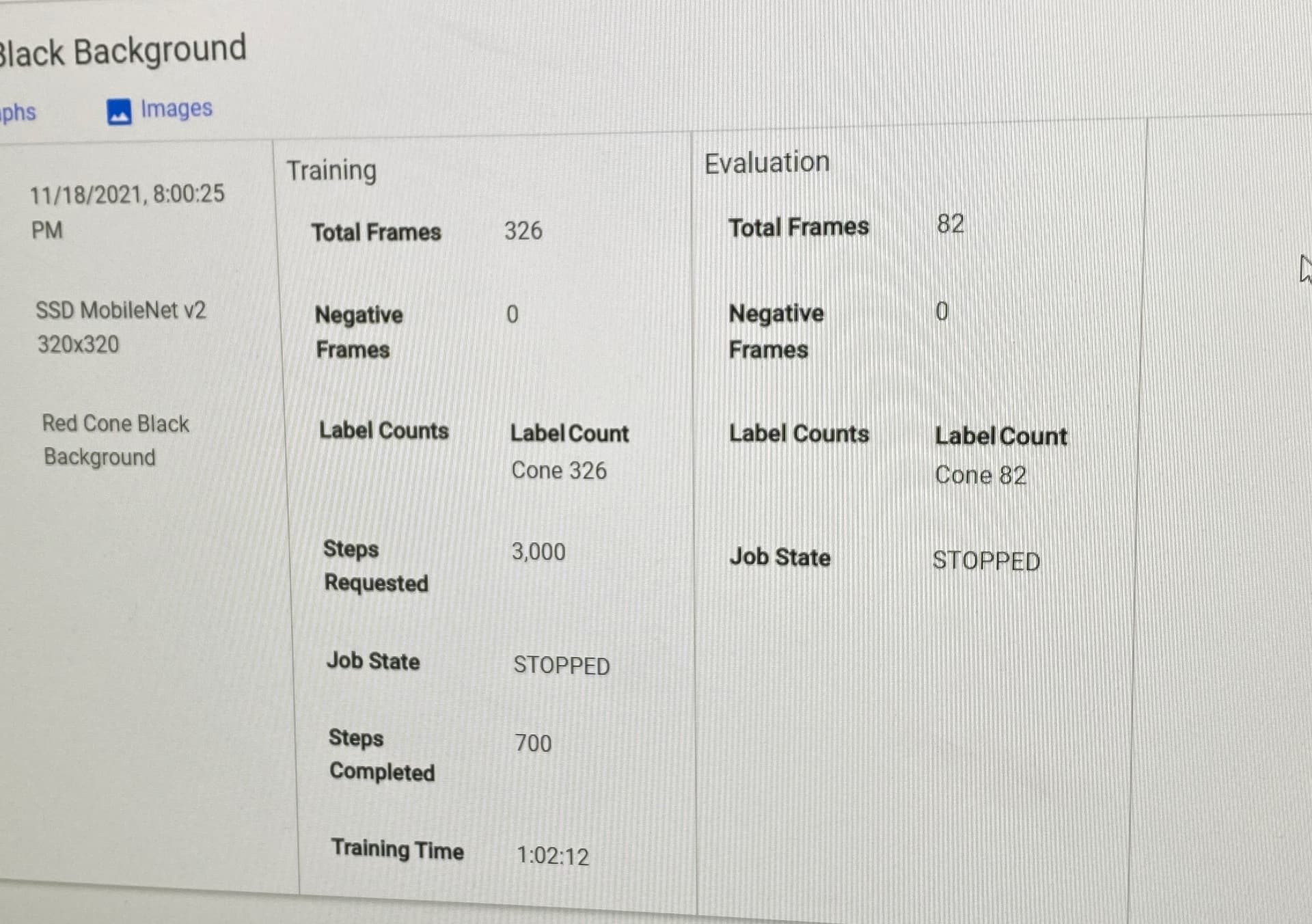
From the screenshot above of the evaluation images for the Red_Cone_Redone model, it looks like you trained for about 500 steps. I think you may need to train for more steps. I suggest 2000 or 3000 steps.
Awesome! Ignoring blurry frames was also something we did when we got ours working! Looking forward to doing this again with our real object once the tool comes on line again.
I’m curious if you looked at your metrics from your original (non-working) model, and what they looked like. Compare the metrics from your “unsuccessful” model and your “successful” model and I bet you’ll see a distinct difference.