Hello, I’m Bret from 4886 Robojunkies.
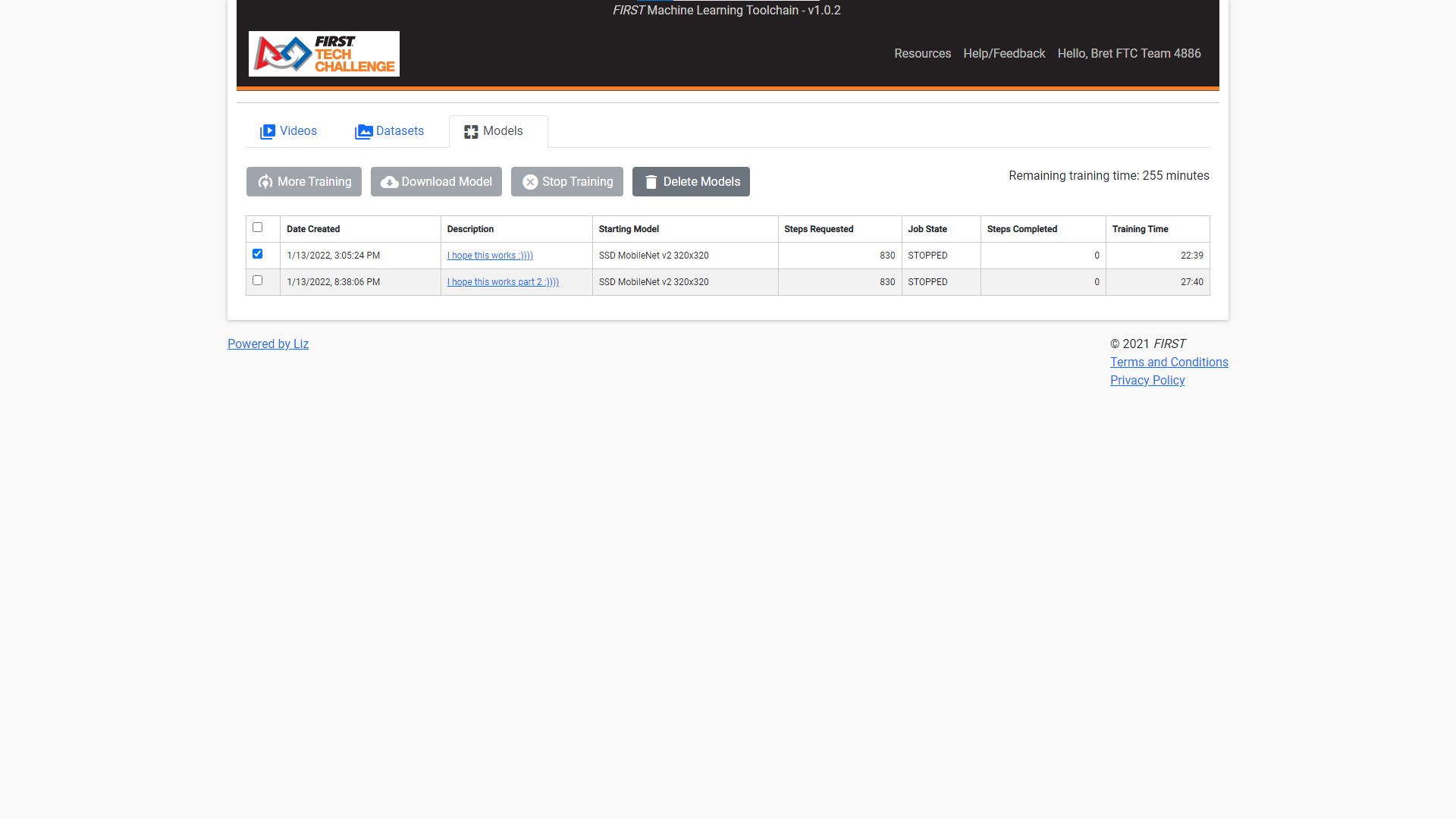
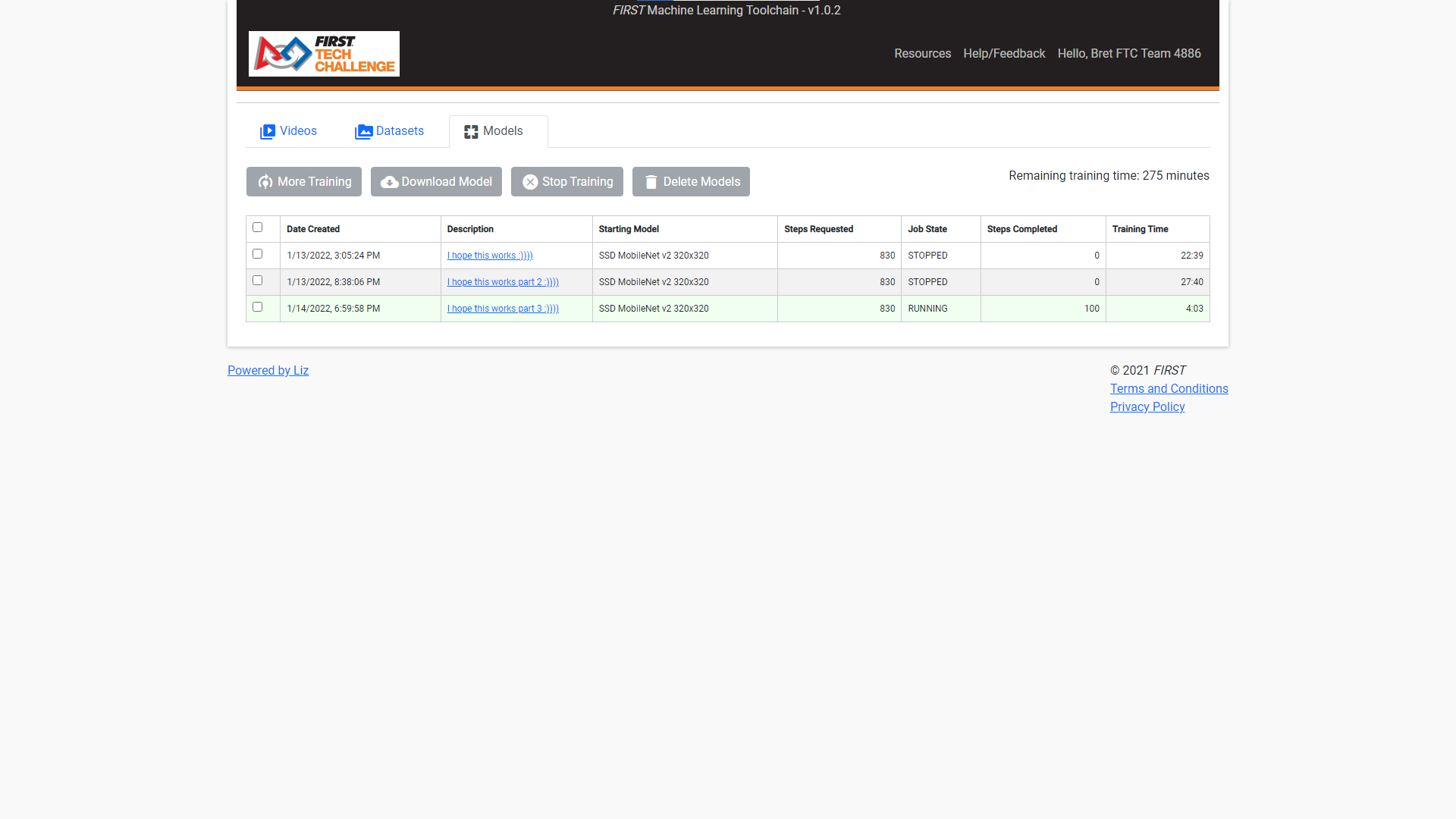
I have followed the steps in the user manual to the best of my ability: I created videos, I selected them to be trained into a dataset, and with the trained dataset, I moved on to creating my first model. For context, I labeled 2 objects, Duck (a yellow rubber ducky) and BlueSphere (our team shipping element).
The dataset I used contains 265 training frames and 66 evaluation frames. With this in mind, I followed the formula provided to get 100 epochs as the manual suggested (I realize this is a rough suggestion, but I wanted to understand my limits first before I went higher in epoch counts). following the formula, I ended up with 830 steps:
100 (recommended epochs) x 265 (training frames) / 32 (the recommended batch size) = about 830 ( working out the math gives 828.125 steps, so i just rounded up)
The problem I have encountered is that if it takes 60 minutes to train 3000 steps if my math was right, I could train my 830 steps in 17 minutes. I settled for 20 minutes so that if for some reason the training lagged “behind schedule” I’d have an extra 3 minutes or so to account for it.
Sadly, after 20 minutes, I discovered that none of my steps were trained. No checkpoints, nothing. I ran the same training practice, but accolated 25 minutes instead, but to no avail. (you’ll notice the timer is a little over these values because it took some time to stop the training.)
My question to anyone who knows what might be going on is, is this a bug in the User Interface? Or have I made a miscalculation somewhere?
Thank you so much,
Bret Bodily 4886 Robojunkies
(See attached:)

(I would love to send more to show you what I mean, but I’m limited to 1 image since I’m a new user. Hopefully this makes sense)